今年,AI 生图领域连续出现爆款。
先是 GPT-4o 生成的吉卜力风格的图像火遍了全网。
紧接着是一张手办照片让 Google 旗下的 Nano Banana 模型火了。
文生图、图生图、多图合成、高保真的文字渲染,还解决了主体性一致的问题,甚至有不少媒体称 Nano Banana 是图片模型的 ChatGPT 时刻。连只提供手办照片生成、按照次数收费的小程序都火了不少。
遗憾的是,Nano Banana 的中文支持仍旧不是太好,不仅是中文提示词生成结果的不确定性,生成的图片中,中文出现问题的概率也更大。
不过没事,国内模型厂商这就来了。这两天,火山引擎推出了豆包·图像创作模型 Seedream 4.0,主打文本、图像的组合输入,实现了多图融合创作、参考生图、组合生图、图像编辑等核心能力,且 主体一致性大幅增强,跟 Nano Banana 相比 并 不逊色。
它也是第一个支持 4K 多模态生图的模型,想到这里,可用性就更宽阔了。
我们第一时间在「火山方舟体验中心」使用了 Seedream 4.0,最多试了同时输入 10 张图片、让它一次性生成 15 张图片的高难度多图融合,也在主体一致性、精准指令编辑以及多图创作等各个维度进行了详细评测。
想知道,除了是一个更适配中国年轻人的 Nano Banana 平替之外,Seedream 4.0 和 Nano Banana 们,会如何影响和推动今天的 AI 创业?
是图片模型们的 DeepSeek 时刻?还是 AI 产品又一次的 「The Bitter Lesson」再现?
01 多图合成能力很惊艳:
文字讲不清楚,就上图!
提个问题,如果你在时尚杂志上看到一张好看的合影,想拉着朋友一起复刻,你会怎么做?
这件事在生活里不难,把杂志照片给朋友看,各自知道摆什么姿势就好了。
但如果想用 AI 生成一张同姿势的合影呢?
普遍的逻辑是,尽力用文字描述这到底是怎么样一种合影姿势,然后大概率生成出来的合影姿势不对,再一点一点用语言矫正。这实在是一种退而求其次的办法。
Seedream 4.0 模型最亮眼的能力,就是能实现「把杂志照片给朋友看并把合影拍了」,这就是多图融合。
——别怀疑,就是字面意思的把怎么摆姿势这件事直接用图片告诉 Seedream 4.0。比如我随便拿一张钢铁侠的照片,再拿一张最近《F1:狂飙飞车》电影里布拉德皮特的剧照,扔给 Seedream 4.0,再给模型传一个勾肩搭背的摆拍姿势,像这样:

然后给一句 prompt:将图 1 男子和图 2 男子合进一张画面,参考图 3 姿势,你就能得到一张破次元壁的魔幻照片。

这次更新的 Seedream 4.0 在模型设计中实现了对文本、单图及多图输入的真正原生多模态支持,能够在同一模型框架下自然支持图像创作、图像编辑、多图融合生成等能力,这种统一化多模态能力让模型能够适配更多复杂场景。而除了多图输入,Seedream 4.0 也支持多图输出。
同样是这组照片,给一个简单的 prompt「故事分镜,参考这两个角色,生成一系列打架的故事」,Seedream 4.0 可以直接把两人带回复联 2 的环境里,甚至皮特还知道要攻击钢铁侠胸口的方舟反应堆。

甚至可以试试再往前走一步,用 Seedream 4.0 来为自己的产品搭一个真实的使用场景。比如利用模型多图输入的能力,把设计好的衣服和裤子,直接搭配在一个你给定的模特身上看看效果。

prompt:给图 3 模特穿上图 1 和图 2 的衣服,并穿上图 4 的鞋子。
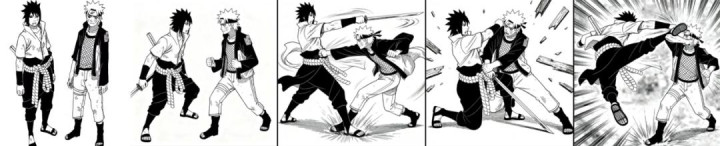
或许用两个漫画人物,能把 Seedream 4.0 多图融合的能力体现得更淋漓尽致。
比如《火影忍者》里的漩涡鸣和佐助。当人物在画风上更加一致,其多图在人物形象保持、身体姿态的协调性上的效果也更加丝滑:
当然,用一句 Prompt 直接生成图像,更像是一场概率的赌博——色彩、构图、细节,大量不可控的随机性潜伏在像素之间。就像一位漫画家不可能每一格分镜都一笔成型,AI 图像生成的真正成熟,也绝不取决于「一次性出图」的偶然完美。实现对图像进行更细粒度的控制,才真正意义上决定了 AI 在图像生成上是否真的可用。
在输入和输出端的多图能力只是 Seedream 4.0 的第一步。在此基础上,Seedream 4.0 强悍的精细编辑能力能保证你可以在一个非常可控的环境下把图片精修到完美。
02 细节编辑能力很强,
更能「抓重点」的图片生成模型
比如,在刚刚那组生成的漫画场面中,要想清除第四张图里有些生硬的碎木板,要如何做到?
只要将这句「把图中飞溅的碎木板元素都清除掉,只保留两个人物的打斗形象」作为 prompt 输入进去就好了:
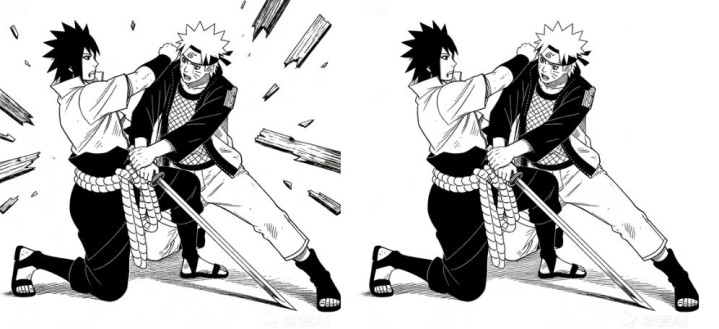
Seedream 4.0 有着非常精准的指令编辑能力,只需对它说一句大白话,Seedream 4.0 就能听懂你的意图,精准执行图像编辑中局部元素的增删、修改和替换。
你可以轻松地说「将画面中的苹果替换成半透明材质」,于是一颗晶莹若琉璃的果体悄然浮现,光影折射都合乎物理规律。

你甚至可以对它说:「把窗外这片城市雪景换成战火。」 ——它不只是听令而行,更是在理解语境的基础上,替你实现从窗外景观到整个画面光影的合理化。

在图像的后期调整过程中,Seedream 4.0 凭借其强大的主体一致性能力,能够在插画、3D 和摄影等等不同创作形态下,从参考图像中抽取关键信息,高质量保持特征的一致性,有效避免了在图像生成的多轮编辑中常见的外观失真、语义错位和风格断裂问题。给到了创作者对图片更大的调整自由度。
比如让「主角」小狗从远景变成特写:

或者让写真照片换个机位:

都说摄影已经是个剪裁的艺术,现在看来甚至连把镜头摆到正确的位置这一点都没有这么重要了...
除了角色保持的能力,Seedream 4.0 也能够实现在保持整体画面的基础上,去微调一些局部细节和质感层面的东西,比如调整服装的褶皱和光影。

03 超快的 4K 生成速度,
文本能力也更厉害了!
一个图片生成模型要走向生产力工具,首先要在生成质量和推理速度上达到非常严苛的专业标准。
凭借推理加速与底层算力优化,Seedream 4.0 实现了不错的文生图性能:秒级出图,极大提升了创作流程的响应性与连续性。
比如简单的海报更换字体,Seedream 4.0 可以轻易完成。

输出分辨率扩展至 4K 级别后,画面细腻度、色彩层次与语义一致性也都达到了商用出版水准。值得一提的是,本次还引入「自适应长宽比机制」——系统能够自动识别生成对象的结构特征或创作意图,动态调整画布比例,从根本上杜绝构图畸变与画面裁切瑕疵。
以同一张海报需求分别使用 Seedream 3.0 与 Seedream 4.0 进行生成对比:后者不仅在清晰度上表现更加优越,在细节刻画、光影自然度与整体审美表达上也实现显著跃升,展现出真正贴合商业设计需求的图像素养。

4K 模式下, 连海报的文字都变得更清晰了。 比如让 Seedream 4.0 出一个 4k 版本的牛肉汉堡手绘教程,手绘文字的表现力让人舒适:

海报制作是平面设计工作流中的高频刚需场景,也恰恰是体现 Seedream 4.0 多模态生成能力的典型场景。在真实的品牌推广中,设计师往往面临的不是单一海报任务,而是需要快速产出同一主题、同一视觉语言、但样式多元的系列海报——这正是 Seedream 4.0 所擅长的。
比如我们挑一张 70 年代(下图左一)的经典海报,要求 Seedream 4.0 将海报分别改为左右排版、包围式排版、三角形排版、中心排版、对称排版的 5 种不同排版。实话实说,其中的几张对图案和文字的变形处理真的非常具有美感。

当然,Seedream 4.0 所能实现的,远不止于单张图像生成——它已经具备了执行更高阶创意任务的能力,例如:从一个品牌 Logo 出发,自动衍生出一整套周边产品的视觉样貌。
而你所需做的,仅仅是上传你的品牌标识,并输入一段再简单不过的提示——比如:
参考这个 LOGO,做一套户外运动品牌视觉设计,品牌名称为「GREEN",包括包装袋、帽子、纸盒、卡片、手环、挂绳等。绿色视觉主色调,趣味、简约现代风格。
剩下的一切,交给 Seedream 4.0。

对于严苛的产品设计团队而言,Seedream 4.0 当前的生成能力在工艺细节、材质表现或局部造型等方面可能仍与量产标准存在差距。但借助强大的指令微调能力,可快速对每张输出样图反复进行局部优化——调整造型、调整配色饱和、简化冗余元素、强化品牌标识露出等等。
经过多轮精修后,最终打磨出的样式图在内部产品会上当个参考图应该是没什么问题了。
04 超强一致性的背后,
是想成为真正的生产力工具
体验到这一步会发现,Seedream 4.0 所呈现的是一种高度贴合人类视觉创作工作流的完整能力。输入端的多模态理解能力降低了只有文字提示词的信息损失,输出端的多图能力带来了图片批量生成时世界观的一致性。
而真正让 Seedream 4.0 在可用性上得到跃迁的,是在单图编辑中所展现出的强大的对自然语言的指令理解和指令遵循能力。Seedream 4.0 的野心不在于去成为社交媒体中传播的 AI 玩具。它要踏入的,是专业工作室、广告创意与数字艺术生产的核心场景,去成为一个真正的生产力工具。
比如,各类产品说明书 的设计制作 已经可以用 Seedream 4.0 搞定了。
在文字处理上突破了以往模型的瓶颈后,Seedream 4.0 能在一定程度上处理处理公式、表格、化学结构、统计图等复杂排版。
同样以 Seedream 3.0 和 Seedream 4.0 做个对比,使用同样 prompt 生成送货机器人的手绘草图,Seedream 4.0 在文字渲染和排版上明显更加精致:

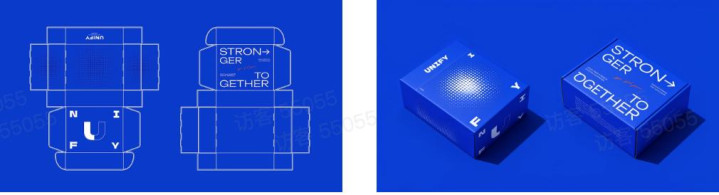
产品包装盒的演示也可以轻易拿下,直接把一个包装盒的展开面设计图纸交给 Seedream 4.0,让它帮你「折」出一个更直观的包装盒演示图。
在美术渲染领域,Seedream 4.0 展现出成为原画师关键生产助手的巨大潜力。
比如,它能够将一张粗糙的线稿,依据用户指令自动施加风格化色彩渲染,不仅支持写实、卡通、水墨等多种视觉风格,还可精准控制色调分布与明暗关系。

更进一步,Seedream 4.0 还能把二维人物线稿转化为三维化、高精度的人物手办造型图,自动补充背面与侧面结构,并生成符合原设动态的立体姿态与材质细节。
这一切不再依赖传统建模软件中繁琐的拓扑、绑骨与贴图流程,而是通过语义理解一气呵成,极大降低了原型设计的门槛与时间成本。
漫画分镜这块,四格漫画可以一步搞定了。
在之前的体验中,我们已经试过用 Seedream 4.0 和角色照片来生成多张的漫画分镜,但模型在这基础上还能做的更多。比如 Seedream 4.0 可以基于连续生图的能力,用生成的图片作为关键帧,实现更加精准可控的多模态生成。

prompt:卡通风格,出一个小狗在家里捣乱的六格连环画
这种从静态到动态的演进,实际上反映了 AI 创作工具正在逐步对齐人类的创作思维模式。当我们构思一个故事或场景时,往往是先从想法(自然语言)形成一幅幅关键画面,然后再将这些画面串联成动态的叙事。Seedream 4.0 的这种能力恰恰模拟了这一认知过程。
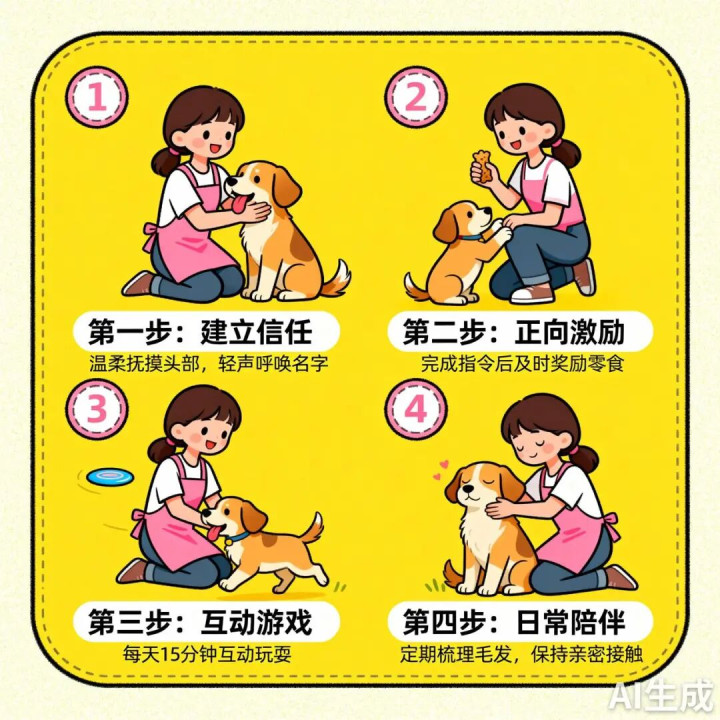
prompt:卡通风格,出一个养狗如何跟小狗做好朋友的教程图,步骤说明要中文。
简单来说,AI 在创意发散与执行效率层面,或许已在某些方面超越人类,但其本质仍是一种服务于人类意图的生产力工具。因此,AI 内容生产的逻辑必须与人类的思维框架对齐,才能真正融入创作流程。从文本到视频的直接跨越,过程中存在天然的画面维度缺失,导致严重的信息损耗,而图像作为中间媒介,正逐渐成为 AI 多模态协作中最关键的「语义枢纽」。
对火山引擎而言,手握文本生成、视频合成、视觉理解与语音模型等多种模态的模型能力,一个强大的图像生成模型——尤其是像 Seedream 4.0 这样凭借上下文工程实现精准可控生成的模型——或许正是那个连接起这一切能力,实现真正多模态模型间的充分「对话」的核心纽带。
而利用上下文工程中把图片生成可控性拉满的 Seedream 4.0 的出现,也给今天的 AI 图片产品的创业,带来了一些新的可能性。
05
支持上下文对话的 Seedream 4.0,
带来了哪些新的创业想象?
因为吉卜力风格而大火的 GPT-4o Image 图像生成模型(model 名字是 GPT-image-1)能力很强,而在此之外,还有一个同样值得注意的地方:API 接口范式的变化。
GPT-4o Image 不仅支持传统图片生成模型的 Image API(单次图片的生成和修改接口) ,还支持文本模型如 GPT 系列默认的 Response API (对话流式接口)。
传统模型的 API 都是「单次请求-单次生成/编辑」,每一步都需要开发者手动管理上下文和结果,无法像文本对话那样自然地连续修改图片。GPT-4o Image 的创新在于:
支持在同一会话中连续迭代图片,每次修改都能自动继承前一步的上下文和图片内容。
API 层面直接维护多轮编辑的状态,无需开发者手动拼接输入输出。
让图片生成和编辑像文本对话一样流畅,极大提升了交互体验和开发效率。
这也是此前主流图片生成模型(如 Stable Diffusion、Flux、DALL-E 2/3)所没有的能力。对于需要复杂创作、反复修改的场景(如设计、内容创作、AI 助手),这是一次重要的来自基模层面的技术突破。
Nano Banana (原名是 Gemini 2.5 Flash Image)原生支持的就是 Gemini 的 GenerateContent API,支持在同一个对话里进行多轮图片的修改、多图合成以及图片+文本生成图片的模式。
这次的 Seedream 4.0 则和 GPT-4o Image 一样,同时支持图片生成 API 和流式响应 API。支持以「再次提交编辑任务(带上上一张图/参考图)」的方式实现多轮复杂对话任务。
这也意味着,仅仅依靠基模的能力提升,很多只能简单生成图片的产品,就可以从一次性调用的「滤镜/出图」工具升级为带上下文的项目式创作工具。
做一些功能复杂的图片产品这件事,变得简单了,因为不需要考虑复杂的工作流编排了;但同时,也变得更难了,因为你需要更全局地去考虑上下文、细分场景的数据积累等等。
AI 图片类产品的创业范式,有了一些新的变化。 会怎么变,新的产品壁垒又在哪里?
我们跟 Lovart 的产品团队聊了聊,作为国内首批接入火山引擎 Seedream 4.0和谷歌 Nano Banana 模型的 AI 产品,他们对于如何用好 Seedream 4.0 有一些经验可以分享。
Q:Seedream 4.0 接入难度大吗?和过去的 FLUX 等模型相比,有什么区别?
A: 适配难度会大一些,因为这模型更「全能」了,可以做生图、改图,在 agent 和 canvas 都有更丰富的使用场景,但需要引入策略的细化。
Q:过往是单次生成图片,到今年这一波的图片可重复修改,用户的使用行为上有什么变化吗?
A: 过去改图主要依赖于手工 PS 或者非常庞杂的 ComfyUI 工作流,现在基本一个基模可以解决 80%,用户抽卡变少,使用参考图、进行多轮修改变多。
Q:Nano B annana 和 Seedream 4.0 这类模型会对 ComfyUI 和 LoRA 有影响吗?
A: 会,这是好的趋势,Comfy 会更多用在批量、重复的任务中,Lora 会用在精细化的准确风格、主体、IP 的微调中,在专业领域仍有些需求。对于第三方图片产品来说,要靠场景测评+分任务+更好的 Infra等工程,在现有模型的基础上把产品做厚。
Q:上下文工程对图片生成类产品重要吗?怎么理解这个重要性?
A: 非常重要,多层上下文,设计知识的上下文、流行趋势 trends 的上下文、品牌风格理念的上下文,任务的上下文,对设计的专业度、精准性、一致性都有很大影响。
倍顺网-配资合作-加杠杆炒股-1万炒股怎么加杠杆提示:文章来自网络,不代表本站观点。